AI Data Training is the hosted Vector Store in Agent Builder Pro. Upload PDFs and manuals or scan website content; documents are chunked and embedded so assistants can retrieve exact passages at chat time (RAG). For curated FAQs and policies that you maintain as markdown, use the free Knowledge Wiki (OKF) instead — no credits required.
Prerequisites
- Free Agent Builder plus active Agent Builder Pro
- API credits for embedding and queries (see credit usage)
On free-only installs, Agent Builder → Knowledge → Vector Store shows an upgrade card. The free Knowledge Wiki tab remains fully usable without Pro.
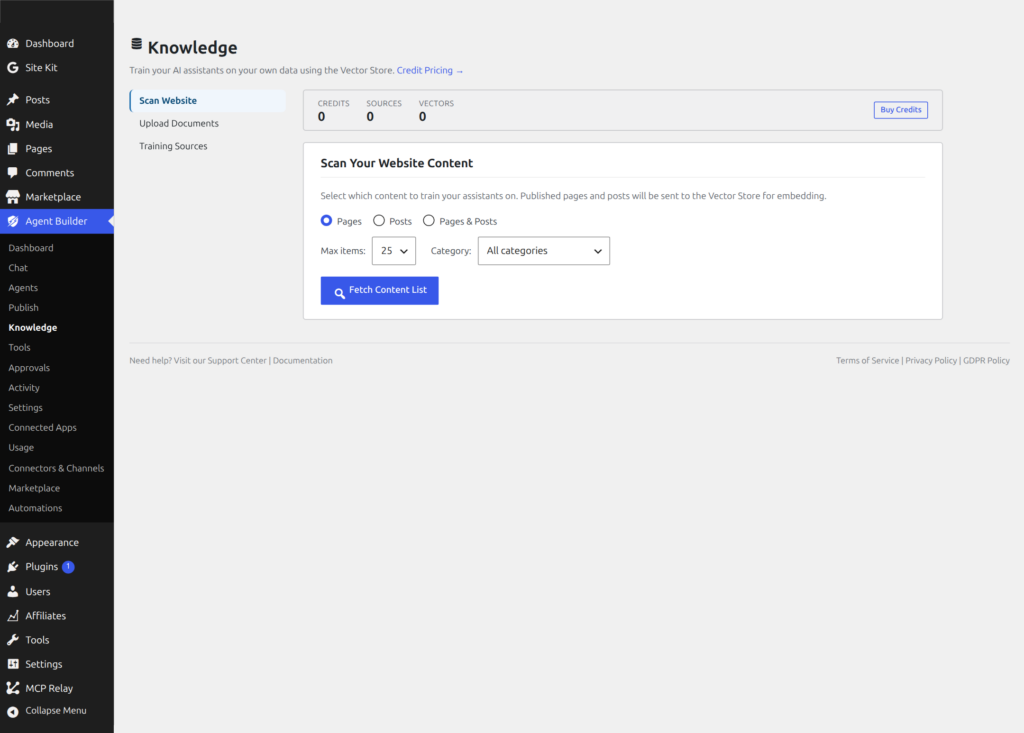
Train assistants on your documents
- In WordPress admin, go to Agent Builder → Knowledge → Vector Store.
- Scan published pages/posts, or upload PDF / TXT files. Large manuals are chunked automatically.
- Wait until the source shows as trained in your private vector namespace.
- Ask an assistant a question the document answers. Pro injects matching passages into context at chat time.
Credit usage
| Operation | Cost | Unit |
|---|---|---|
| Embed / Train | ~0.7–1 credit | per 1,000 tokens of source text (see live pricing) |
| Semantic Query | ~1 credit | per search issued for an assistant |
| Document Delete | Free | always |
Full packages and rates are on the API Credits page.
Privacy & data handling
- Isolated namespace — your vector store is separate from every other customer.
- Encrypted — TLS in transit; at-rest encryption on the managed backend.
- Not used for foundation model training — content is processed under the service DPA.
- Deletable — remove any document or the whole corpus at any time (GDPR Article 17).
WP-CLI (Pro)
wp agent rag status|train|upload|search|delete — manage the vector store from the terminal.
Troubleshooting
- Upgrade card instead of train UI — install and activate Agent Builder Pro.
- No license key — activate your Pro license, then retry.
- Assistant ignores documents — confirm sources are trained and credit balance covers queries; ask a question answered in the source text.
- Out of credits — top up on the API Credits page; deletion stays free.
Related Articles
- Knowledge Wiki (OKF) — free local curated knowledge
- Vector Store & RAG Integration — technical reference
- API Credits
- Documentation